Reinforcement Learning Part 4: NHL94 and F-Zero
- Jonathan Cocks

- Jun 6, 2021
- 3 min read
This is the long-overdue 4th instalment of my blog post series on reinforcement learning. Due to some craziness at work and in my personal life over the last few months I've had to take a break from documenting this project. I finished it months ago, but let's pick up right where we left off on here.
In order to learn more about the flavors of reinforcement learning we'll be using in this and subsequent posts, start with Part one of this blog post series. To get your RL environment set up to run some examples, see Part two. Part three looked at a use case involving the game Tetris.
Our results applying some of these principles to Tetris in the last post were fairly underwhelming. Due to the sparse nature of the reward function we weren't able to successfully train an agent. There were a couple of other use cases that I attempted before I was able to build an agent that functioned in a useful way (much more in next post). The next one I looked at was NHL94 on Sega Genesis.

I'm a hockey fan and have spent a ton of hours with this game. I had an inkling that using goals as a reward function here would absolutely be too sparse as well, but I thought maybe I could craft a more sophisticated reward function that captured more dynamic rewards based on the state of the system.
Some things I considered:
- Possession: reward agent for possessing the puck
- Zone time: assign rewards for keeping the puck in the offensive zone, smaller penalty for extended time in the defensive zone
- Shots on net: large rewards for generating shots on net, negative rewards for allowing shots on own net
Sadly, there were a bunch of issues that I encountered before I was even able to implement a useful reward function.
RAM values were very difficult to find and extract. The way this game is architected made no sense to me and the variable space was huge. I thought I was able to extract variables representing the active player and puck position, but those seemed notoriously unreliable. There was no universal indicator that I could find that indicated which team had possession, so I needed to code pixel-position computations that would infer possession based on locations of players and the puck, which was very rough.
Agent only controls one player at a time. Even armed with some somewhat unreliable data about the state of the system, the agent only controls a single player at a time, diluting the impact of any action on such a simplistic reward function.
Even shots as reward was quite sparse. The set of actions leading up to even a shot, much less a goal are potentially very lengthy and chaotic, with questionable causal link between actions and reward. Which is likely because...
Hockey itself is a very fast, chaotic sport.
Once I found some variables to extract I wrote a pretty basic reward function, but there were a few things that conspired to make this another frustrating and ultimately fruitless experience. The variables were unreliable, the rewards were computed inaccurately and the agent basically learned that putting "pucks-in-deep" was the desired behavior. 200 hockey men would be proud, but what it meant in reality was that the agent simply iced the puck repeatedly, not learning anything about the system, the game or how to play it effectively.
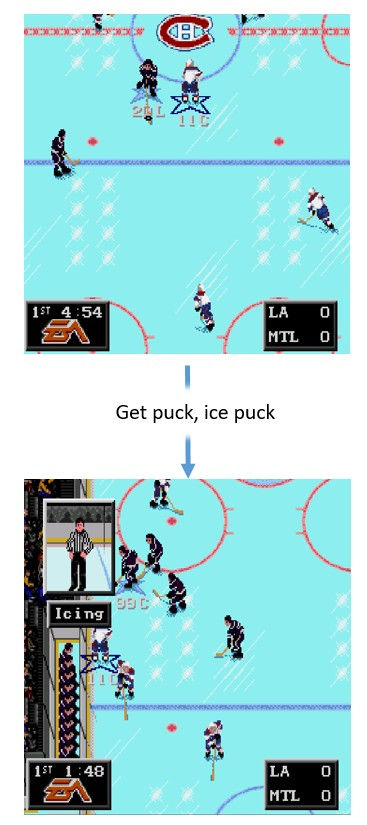
I think if I could sum up what I'd learned to this point it's twofold:
Reward functions are brittle and must be defined carefully. Too sparse the agent cannot discern a causal relationship between actions and success. Too rough and it may learn the wrong behavior. Corner-cases can mess things up very easily.
Garbage in, garbage out. Like literally everything else in this field, if you don't have good data you have nothing. The difficulty in extracting reliable data from RAM to feed to the reward function is simply too high for some games.
I think if armed with some more reliable input data I might be able train a moderately effective agent here. Sadly, documented RAM maps aren't available for this game anywhere I could find on the interwebs.
After this I did some Googling and tried to replicate the results from F-Zero in this series of videos.
I had some issues, but I chalked it up to not having a GPU-capable rig to train the models on. Across these experiments I also started to suspect that the complexity of the state input (effectively an image of the emulator screen) was contributing to the system taking a hugely long time to converge for all of these use cases. I started to percolate some thoughts around how we could simplify this state representation to allow much faster training times. Regardless, the F-Zero use case was what pushed me to look at Super Mario Kart as the final, and ultimately only successful, use case I would look at. Check out the details here.



Comments